Hadoop HDFS搭建
摘要
1 环境准备
1.1 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld1.2 关闭selinux
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config1.3 安装jdk
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel2 Hadoop安装
Hadoop部署模式有:本地模式、伪分布模式、完全分布式模式、HA完全分布式模式。
区分的依据是NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程、几个机器。
| 模式名称 | 各个模块占用的JVM进程数 | 各个模块运行在几个机器数上 |
|---|---|---|
| 本地模式 | 1个 | 1个 |
| 伪分布式模式 | N个 | 1个 |
| 完全分布式模式 | N个 | N个 |
| HA完全分布式 | N个 | N个 |
2.1 本地模式安装
本地模式是最简单的模式,所有模块都运行与一个JVM进程中,使用的本地文件系统,而不是HDFS,本地模式主要是用于本地开发过程中的运行调试用。下载hadoop安装包后不用任何设置,默认的就是本地模式。
下载Hadoop
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz解压
tar zxf hadoop-3.1.2.tar.gz
mv hadoop-3.1.2 /usr/local/hadoop配置环境变量
### JAVA Configuration ###
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64/
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
### Hadoop Configuration ###
export HADOOP_HOME=/usr/local/hadoop
export PATH=:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin立即生效
source /etc/profile运行Hadoop自带的MapReduce程序,验证
先在/data/input目录下创建一个data.txt文件,output目录不能提前创建,然后在程序所在目录执行如下命令:
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /data/input/data.txt /data/output/
本地模式下,MapReduce的输出是输出到本地。成功后,会在output目录下生成两个文件

Bug
在执行上面的MapReduce时,会出现如下的bug:

可以参考:
https://issues.apache.org/jira/browse/MAPREDUCE-6835
https://issues.apache.org/jira/browse/YARN-4322
注:实际上,在Hadoop本地模式中,只是将MapReduce程序作为普通的Java程序来执行,并不需要Hadoop的HDFS和Yarn支持。
2.2 Hadoop伪分布式模式安装
伪分布式模式在单机上运行,模拟全分布式环境,具有Hadoop的主要功能。
在本地模式基础之上,再修改如下配置文件即可。
2.2.1 配置core-site.xml
vi etc/hadoop/core-site.xml<configuration>
<property>
<!-- 配置NameNode地址 -->
<name>fs.defaultFS</name>
<value>hdfs://192.168.11.72:9000</value>
</property>
<property>
<!-- 保存HDFS临时数据的目录 -->
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>fs.defaultFS
配置NameNode的地址,通信端口号是9000。主机名,也可以使用IP地址。
hadoop.tmp.dir
Hadoop临时目录,比如HDFS的NameNode数据默认都存放这个目录下,查看*-default.xml等默认配置文件,就可以看到很多依赖${hadoop.tmp.dir}的配置。默认的hadoop.tmp.dir是/tmp/hadoop-${user.name},此时有个问题就是NameNode会将HDFS的元数据存储在这个/tmp目录下,如果操作系统重启了,系统会清空/tmp目录下的东西,导致NameNode元数据丢失,是个非常严重的问题,所以应该修改这个路径。
2.2.2 配置hdfs-site.xml
vi etc/hadoop/hdfs-site.xml<configuration>
<property>
<!-- HDFS数据冗余度,默认3 -->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<!-- 是否开启HDFS权限检查,默认true -->
<name>dfs.permissions</name>
<value>true</value>
</property>
<property>
<!-- 配置NameNode地址 -->
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>dfs.replication
配置数据的副本数。因为这里是伪分布式环境只有一个节点,所以这里设置为1。
dfs.permissions
配置HDFS的权限检查。默认是true,也就是开启权限检查。可以不配置,这里只是为了说明。
dfs.namenode.http-address
配置hdfs的NameNode的ip地址、端口
2.2.3 配置mapred-site.xml
vi etc/hadoop/mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>mapreduce.framework.name
配置mapreduce程序执行的框架名称:yarn。yarn是资源管理器框架。
2.2.4 配置yarn-site.xml
vi etc/hadoop/yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.11.72</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>yarn.resourcemanager.hostname
指定了Resourcemanager运行在哪个节点上。
yarn.nodemanager.aux-services
配置了yarn的默认混洗方式,选择为mapreduce的默认混洗算法。
2.2.5 格式化Namenode
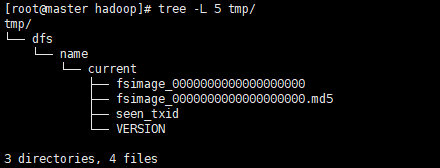
hdfs namenode -format格式化Namenode(实际生成格式化目录/usr/local/hadoop/tmp)。格式化成功后

tmp文件夹目录结构
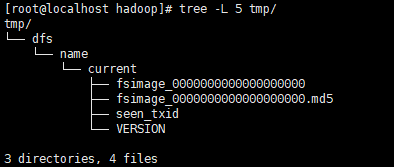
fsimage是NameNode元数据在内存满了后,持久化保存到的文件。
fsimage*.md5 是校验文件,用于校验fsimage的完整性。
seen_txid 是hadoop的版本
VERSION文件里
namespaceID:NameNode的唯一ID。
clusterID:集群ID,NameNode和DataNode的集群ID应该一致,表明是一个集群。
2.2.6 启动集群
start-all.sh或
分别执行start-dfs.sh和start-yarn.sh
ERROR: Attempting to operate on hdfs secondarynamenode as root ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
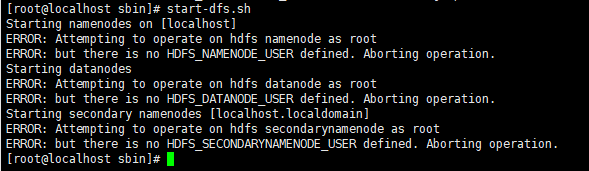
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=rootPermission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
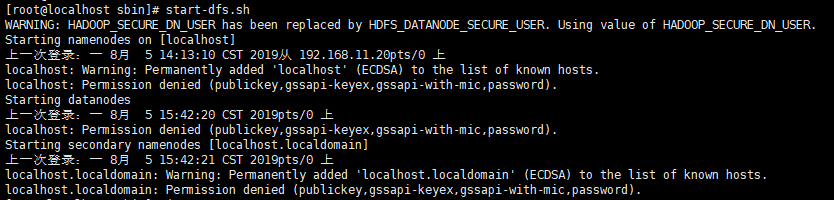
设置ssh免密登录协议
ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keysERROR: JAVA_HOME is not set and could not be found.

需要到hadoop/etc/hadpoop/hadoop-env.sh加上JAVA_HOME的路径
vi etc/hadoop/hadoop-env.sh
加入
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64/JPS命令查看是否已经启动成功
YARN的Web客户端端口默认是8088
HDFS的web页面端口默认是50070
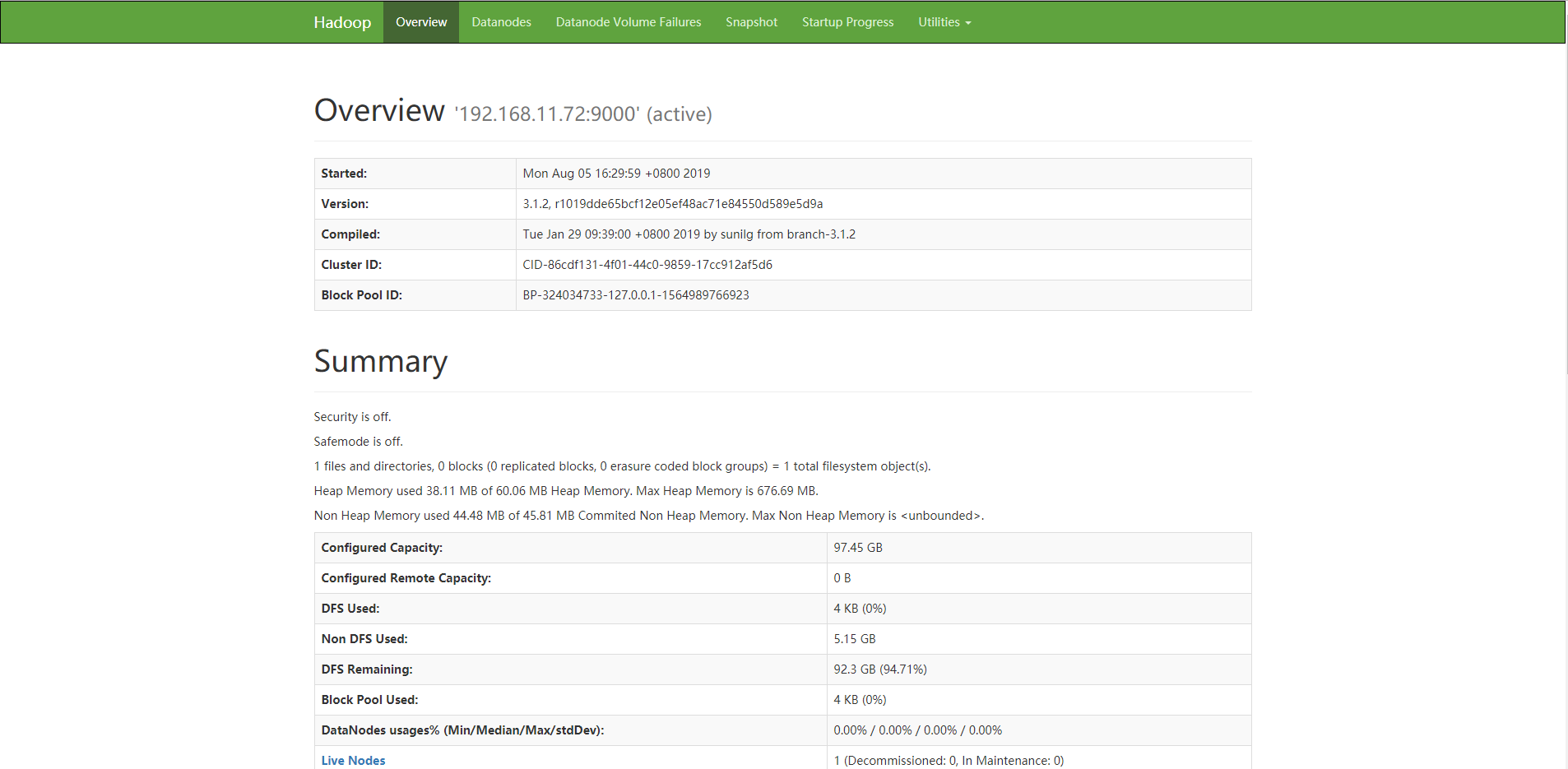
2.2.7 测试
创建数据
在本地模式中,单词统计的数据输入和输出都是在Linux本地目录,而在伪分布模式中,数据的输入和输出都是HDFS,所以需要在HDFS上准备输入数据。分别执行如下命令:
hdfs dfs -mkdir /input
hdfs dfs -put /data/input/data.txt /input在HDFS上创建input目录,将数据data.txt上传至该目录。
执行MapReduce程序
在程序所在目录执行如下命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /input/data.txt /outputoutput目录不能提前创建
错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster

在命令行下输入如下命令,并将返回的地址复制
hadoop classpath编辑yarn-site.xml
vi etc/hadoop/yarn-site.xml添加
<property>
<name>yarn.application.classpath</name>
<value>输入hadoop classpath获取的路径</value>
</property>在所有的Master和Slave节点进行如上设置,设置完毕后重启Hadoop集群,重新运行刚才的MapReduce程序,成功运行。
成功后,会在HDFS的/output目录下生成两个文件,结果如下:
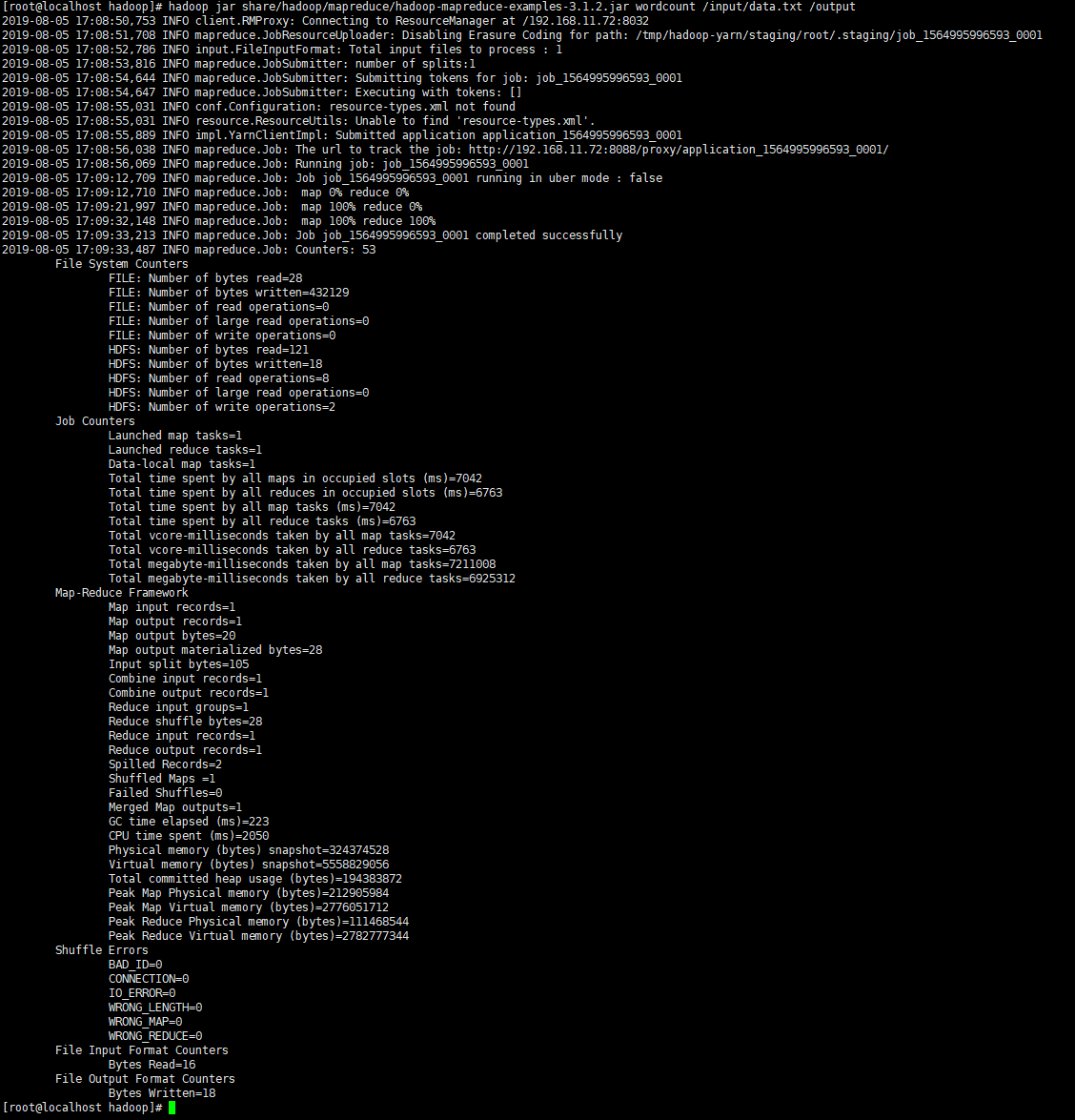

和本地模式产生的数据是一样的,只是一个存在Linux本地目录,另一个存在HDFS上(事实上它的数据也在Linux上,具体在/usr/local/hadoop/tmp/dfs/data/current下)。
2.3 全分布式安装
完全分部式是真正利用多台Linux主机来进行部署Hadoop,对Linux机器集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上。
2.3.1 环境
| 主机名 | IP | 角色 |
|---|---|---|
| master.hadoop.cn | 192.168.0.97 | NameNode / SecondaryNameNode / ResourceManager |
| node1.hadoop.cn | 192.168.0.98 | DataNode / NodeManager |
| node2.hadoop.cn | 192.168.0.99 | DataNode / NodeManager |
关闭防火墙,关闭selinux,安装jdk,下载解压hadoop,配置环境变量(过程参考本地模式安装)
2.3.2 修改hosts
vi /etc/hosts添加以下信息
192.168.0.97 master.hadoop.cn
192.168.0.98 node1.hadoop.cn
192.168.0.99 node2.hadoop.cn配置免密码登录后将hosts拷贝至其他主机
scp -r /etc/hosts root@node1.hadoop.cn:/etc/hosts
scp -r /etc/hosts root@node2.hadoop.cn:/etc/hosts2.3.3 免密码登录
免密码登录自身【三台】
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keysmaster免密码登录其他机器(master免密码登录node)【单台,只需在master上执行】
ssh-copy-id -i ~/.ssh/id_rsa.pub master.hadoop.cn
ssh-copy-id -i ~/.ssh/id_rsa.pub node1.hadoop.cn
ssh-copy-id -i ~/.ssh/id_rsa.pub node2.hadoop.cn将免密码登录配置放在第一步,主要是因为免密码登录配置成功后,远程拷贝时不用再输入密码确认,非常方便。
2.3.4 修改配置文件
共需要配置/usr/local/hadoop/etc/hadoop/下的六个个文件,分别是hadoop-env.sh、core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、workers
2.3.4.1 配置hadoop-env.sh
在本地模式下,可以不配置JDK,但是全分布式模式必须要配置,不然启动集群时,会报如下错误:
ERROR: JAVA_HOME is not set and could not be found.
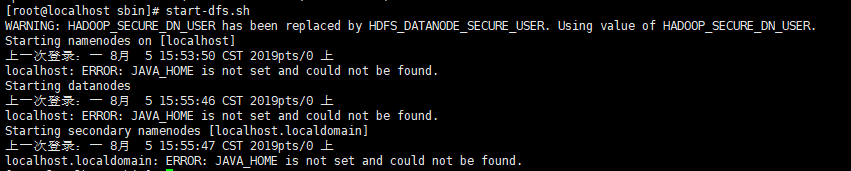
vi etc/hadoop/hadoop-env.sh
加入
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-0.el7_6.x86_64/2.3.4.2 配置core-site.xml
vi etc/hadoop/core-site.xml<configuration>
<property>
<!-- 配置NameNode地址 -->
<name>fs.defaultFS</name>
<value>hdfs://master.hadoop.cn:9000</value>
</property>
<property>
<!-- 保存HDFS临时数据的目录 -->
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>NameNode为master.hadoop.cn
2.3.4.3 配置hdfs-site.xml
vi etc/hadoop/hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master.hadoop.cn:50090</value>
</property>
<property>
<!-- HDFS数据冗余度,默认3 -->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!-- 是否开启HDFS权限检查,默认true -->
<name>dfs.permissions</name>
<value>true</value>
</property>
<property>
<!-- 配置NameNode地址 -->
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>dfs.namenode.secondary.http-address是指定secondaryNameNode的http访问地址和端口号,因为在规划中,我们将master规划为SecondaryNameNode服务器。
dfs.replication数据副本数配置为2,默认是3,这里只有两个DataNode,所以配置为2。
2.3.4.4 配置yarn-site.xml
vi etc/hadoop/yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.hadoop.cn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>输入hadoop classpath获取的路径</value>
</property>
</configuration>ResourceManager节点主机名改为master.hadoop.cn。
2.3.4.5 配置mapred-site.xml
vi etc/hadoop/mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>2.3.4.6 配置workers
vi etc/hadoop/workersnode1.hadoop.cn
node2.hadoop.cnworkers文件是指定HDFS上有哪些DataNode节点。
2.3.5 其他节点配置
将master的hadoop目录远程拷贝到node1和node2上,命令如下:
scp -r /usr/local/hadoop root@node1.hadoop.cn:/usr/local/
scp -r /usr/local/hadoop root@node2.hadoop.cn:/usr/local/2.3.6 格式化NameNode
只有首次部署才可使用,谨慎操作,只在master上操作
hdfs namenode -format
与伪分布模式相同,成功后,如图
注意:
如果需要重新格式化NameNode,需要先将原来NameNode和DataNode下的文件全部删除,不然会报错。NameNode和DataNode所在目录是在
core-site.xml中hadoop.tmp.dir、dfs.namenode.name.dir、dfs.datanode.data.dir属性配置的。因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中(VERSION文件所在目录为
dfs/name/current和dfs/data/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致NameNode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,不一致时会报错。另一种方法是格式化时指定集群ID参数,指定为旧的集群ID。
2.3.7 启动
在master上执行集群启动命令start-all.sh
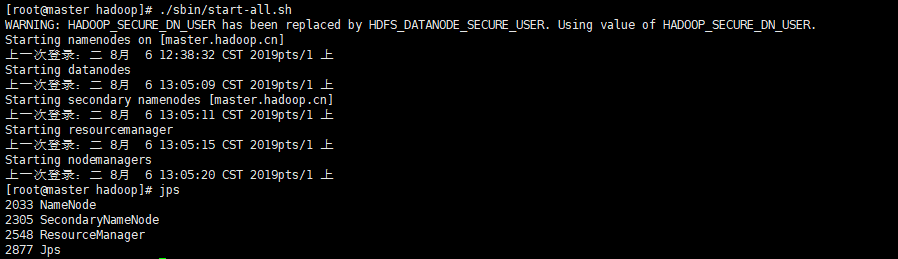
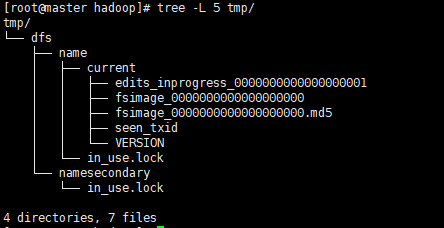
正常情况下,master上tmp目录下有name和namesecondary两个目录
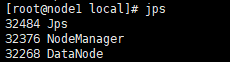
node1
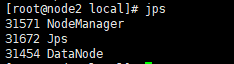
node2
2.3.8 测试
查看HDFS Web页面
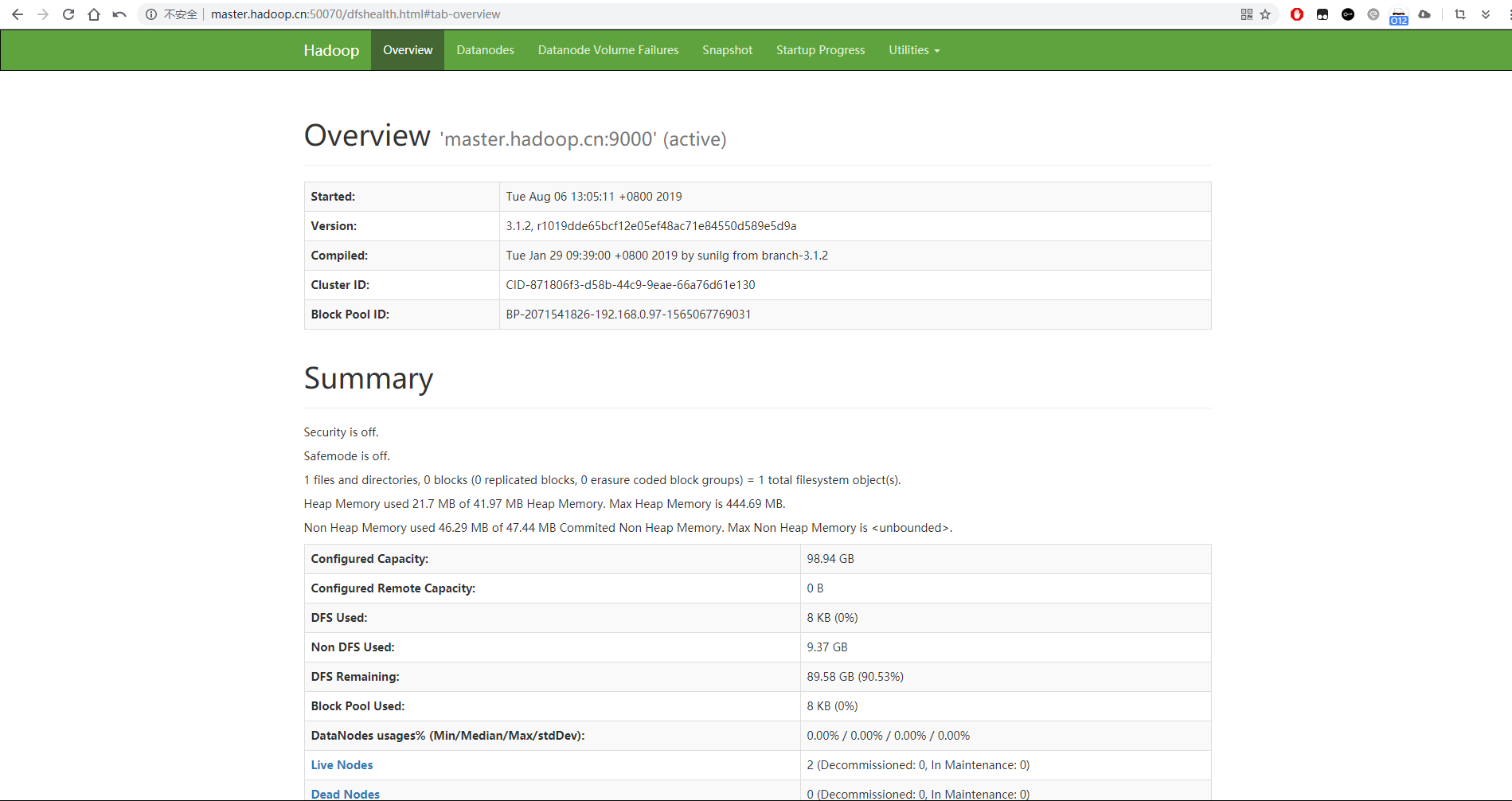
查看YARN Web 页面
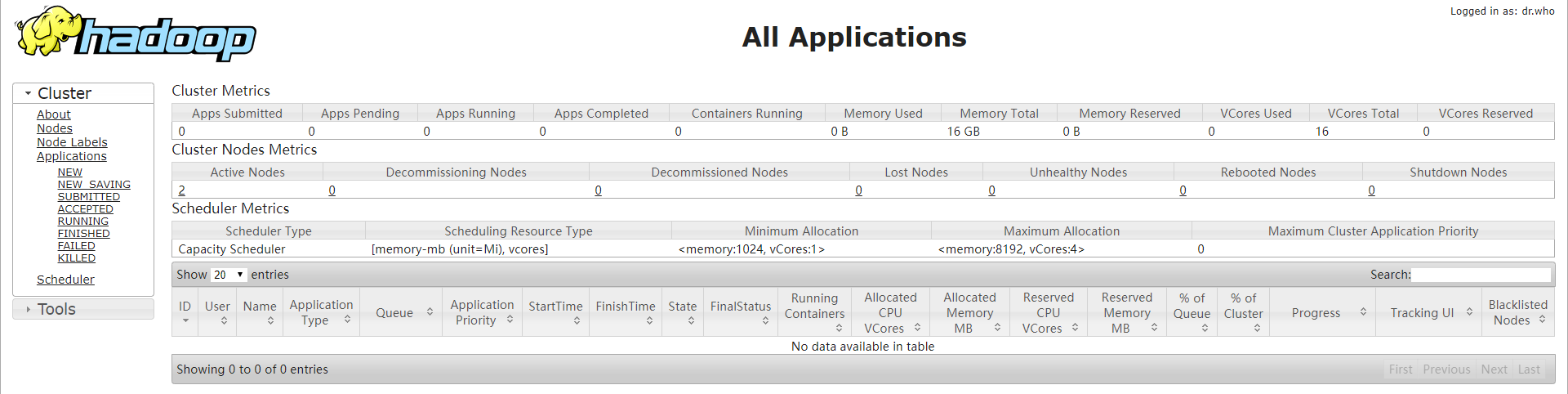
测试与伪分布相同,执行MapReduce程序。略。
3 Hadoop各个功能模块的理解
3.0.8.1 HDFS模块
HDFS负责大数据的存储,通过将大文件分块后进行分布式存储方式,突破了服务器硬盘大小的限制,解决了单台机器无法存储大文件的问题,HDFS是个相对独立的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
3.0.8.2 YARN模块
YARN是一个通用的资源协同和任务调度框架,是为了解决Hadoop1.x中MapReduce里NameNode负载太大和其他问题而创建的一个框架。
YARN是个通用框架,不止可以运行MapReduce,还可以运行Spark、Storm等其他计算框架。
3.0.8.3 MapReduce模块
MapReduce是一个计算框架,它给出了一种数据处理的方式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。它只适用于大数据的离线处理,对实时性要求很高的应用不适用。