使用kubeadm安装Kubernetes1.15
摘要
kubeadm是Kubernetes官方提供的用于快速安装Kubernetes集群的工具,伴随Kubernetes每个版本的发布都会同步更新,kubeadm会对集群配置方面的一些实践做调整,通过实验kubeadm可以学习到Kubernetes官方在集群配置上一些新的最佳实践。
最近发布的Kubernetes 1.15中,kubeadm对HA集群的配置已经达到beta可用,说明kubeadm距离生产环境中可用的距离越来越近了。
1 1.准备
1.1 1.1 系统配置
在安装之前,需要先做如下准备。两台CentOS 7.6主机如下,修改hosts
| IP | 主机名 |
|---|---|
| 192.168.0.7 | k8s-master |
| 192.168.0.8 | k8s-node1 |
如果各个主机启用了防火墙,需要开放Kubernetes各个组件所需要的端口,可以查看Installing kubeadm中的Check required ports一节。
这里防止不必要的麻烦在各节点禁用防火墙:
systemctl stop firewalld
systemctl disable firewalld禁用selinux:
setenforce 0
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config创建/etc/sysctl.d/k8s.conf文件,添加如下内容:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1执行命令使修改生效。
modprobe br_netfilter
sysctl -p /etc/sysctl.d/k8s.conf1.2 1.2 kube-proxy开启ipvs的前置条件
由于ipvs已经加入到了内核的主干,所以为kube-proxy开启ipvs的前提需要加载以下的内核模块:
- ip_vs
- ip_vs_rr
- ip_vs_wrr
- ip_vs_sh
- nf_conntrack_ipv4
在所有的Kubernetes节点master和node上执行以下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4上面脚本创建了/etc/sysconfig/modules/ipvs.modules的文件,保证在节点重启后能自动加载所需模块。
查看是否已经正确加载所需的内核模块
lsmod | grep -e ip_vs -e nf_conntrack_ipv4接下来还需要确保各个节点上已经安装了ipset软件包
yum install ipset为了便于查看ipvs的代理规则,最好安装一下管理工具ipvsadm
yum install ipvsadm如果以上前提条件如果不满足,则即使kube-proxy的配置开启了ipvs模式,也会退回到iptables模式。
1.3 1.3 安装Docker
Kubernetes从1.6开始使用CRI(Container Runtime Interface)容器运行时接口。默认的容器运行时仍然是Docker,使用的是kubelet中内置dockershim CRI实现。
安装docker的yum源:
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum makecache fast查看最新的Docker版本:
yum list docker-ce.x86_64 --showduplicates |sort -rKubernetes 1.15当前支持的docker版本列表是1.13.1, 17.03, 17.06, 17.09, 18.06, 18.09。 这里在各节点安装docker的18.09.7版本。
yum install -y --setopt=obsoletes=0 \
docker-ce-18.09.7-3.el7
systemctl start docker
systemctl enable docker确认一下iptables filter表中FOWARD链的默认策略(pllicy)为ACCEPT。
iptables -nvL
Chain INPUT (policy ACCEPT 263 packets, 19209 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DOCKER-USER all -- * * 0.0.0.0/0 0.0.0.0/0
0 0 DOCKER-ISOLATION-STAGE-1 all -- * * 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- * docker0 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
0 0 DOCKER all -- * docker0 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- docker0 !docker0 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- docker0 docker0 0.0.0.0/0 0.0.0.0/01.4 1.4 修改docker cgroup driver为systemd
根据文档CRI installation中的内容,对于使用systemd作为init system的Linux的发行版,使用systemd作为docker的cgroup driver可以确保服务器节点在资源紧张的情况更加稳定,因此这里修改各个节点上docker的cgroup driver为systemd。
创建或修改/etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}重启docker
systemctl restart docker
docker info | grep Cgroup
Cgroup Driver: systemd2 2.使用kubeadm部署Kubernetes
2.1 2.1 安装kubeadm和kubelet
下面在各节点安装kubeadm和kubelet:
配置国内Kubernetes源
参考阿里云
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOFyum install -y kubelet kubeadm kubectl
systemctl enable kubelet从安装结果可以看出还安装了cri-tools, kubernetes-cni, socat三个依赖:
- 官方从Kubernetes 1.14开始将cni依赖升级到了0.7.5版本
- socat是kubelet的依赖
- cri-tools是CRI(Container Runtime Interface)容器运行时接口的命令行工具
运行kubelet –help可以看到原来kubelet的绝大多数命令行flag参数都被DEPRECATED了
而官方推荐我们使用–config指定配置文件,并在配置文件中指定原来这些flag所配置的内容。具体内容可以查看这里Set Kubelet parameters via a config file。这也是Kubernetes为了支持动态Kubelet配置(Dynamic Kubelet Configuration)才这么做的,参考Reconfigure a Node’s Kubelet in a Live Cluster。
kubelet的配置文件必须是json或yaml格式,具体可查看这里。
Kubelet负责与其他节点集群通信,并进行本节点Pod和容器生命周期的管理。Kubeadm是Kubernetes的自动化部署工具,降低了部署难度,提高效率。Kubectl是Kubernetes集群管理工具。
Kubernetes 1.8开始要求关闭系统的Swap,如果不关闭,默认配置下kubelet将无法启动。
关闭Swap
swapoff -a修改 /etc/fstab 文件,注释掉 SWAP 的自动挂载,使用free -m确认swap已经关闭。 swappiness参数调整,修改/etc/sysctl.d/k8s.conf添加下面一行:
vm.swappiness=0使修改生效
sysctl -p /etc/sysctl.d/k8s.conf因为这里本次用于测试两台主机上还运行其他服务,关闭swap可能会对其他服务产生影响,所以这里修改kubelet的配置去掉这个限制。 使用kubelet的启动参数–fail-swap-on=false去掉必须关闭Swap的限制,修改/etc/sysconfig/kubelet,加入:
KUBELET_EXTRA_ARGS=--fail-swap-on=false2.2 2.2 使用kubeadm init初始化集群
注:在master节点上进行如下操作
在master进行Kubernetes集群初始化。
kubeadm init --kubernetes-version=1.15.1 \
--apiserver-advertise-address=192.168.0.7 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16定义POD的网段为: 10.244.0.0/16, api server地址就是master本机IP地址。
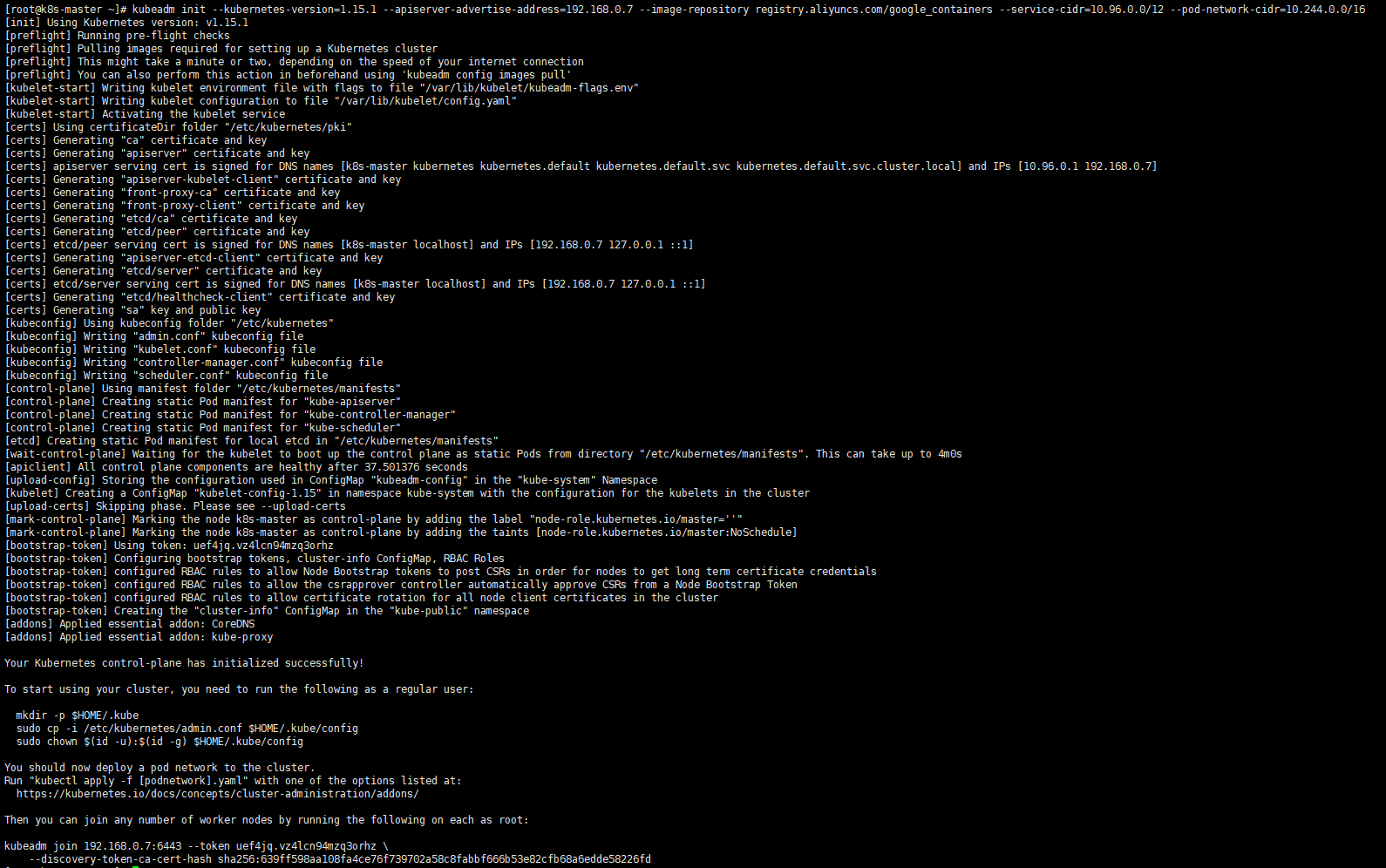
这一步很关键,由于kubeadm 默认从官网k8s.grc.io下载所需镜像,国内无法访问,因此需要通过–image-repository指定阿里云镜像仓库地址,很多新手初次部署都卡在此环节无法进行后续配置。
集群初始化成功后返回信息记录了完成的初始化输出的内容,根据输出的内容基本上可以看出手动初始化安装一个Kubernetes集群所需要的关键步骤。 其中有以下关键内容:
[kubelet-start] 生成kubelet的配置文件”/var/lib/kubelet/config.yaml”
[certs]生成相关的各种证书
[kubeconfig]生成相关的kubeconfig文件
[control-plane]使用/etc/kubernetes/manifests目录中的yaml文件创建apiserver、controller-manager、scheduler的静态pod
[bootstraptoken]生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
下面的命令是配置常规用户如何使用kubectl访问集群:
配置kubectl工具
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config最后给出了将节点加入集群的命令,记录生成的最后部分内容,此内容需要在其它节点加入Kubernetes集群时执行。
kubeadm join 192.168.0.7:6443 --token uef4jq.vz4lcn94mzq3orhz \
--discovery-token-ca-cert-hash sha256:639ff598aa108fa4ce76f739702a58c8fabbf666b53e82cfb68a6edde58226fd
查看一下集群状态,确认个组件都处于healthy状态:
kubectl get nodes
kubectl get cs集群初始化如果遇到问题,可以使用下面的命令进行清理:
kubeadm reset
ifconfig cni0 down
ip link delete cni0
ifconfig flannel.1 down
ip link delete flannel.1
rm -rf /var/lib/cni/2.3 2.3 安装Pod Network(只在主节点执行)
安装flannel network add-on:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/a70459be0084506e4ec919aa1c114638878db11b/Documentation/kube-flannel.yml如果Node有多个网卡的话,参考flannel issues 39701,目前需要在kube-flannel.yml中使用–iface参数指定集群主机内网网卡的名称,否则可能会出现dns无法解析。需要将kube-flannel.yml下载到本地,flanneld启动参数加上–iface=<iface-name>

containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.11.0-amd64
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=ens192
使用kubectl get pod -all-namespaces -o wide确保所有的Pod都处于Running状态。
# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5c98db65d4-dr8lf 1/1 Running 0 52m
coredns-5c98db65d4-lp8dg 1/1 Running 0 52m
etcd-node1 1/1 Running 0 51m
kube-apiserver-node1 1/1 Running 0 51m
kube-controller-manager-node1 1/1 Running 0 51m
kube-flannel-ds-amd64-mm296 1/1 Running 0 44s
kube-proxy-kchkf 1/1 Running 0 52m
kube-scheduler-node1 1/1 Running 0 51m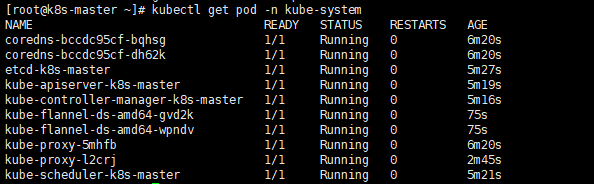
2.4 2.4 测试集群DNS是否可用
# kubectl run curl --image=radial/busyboxplus:curl -it
kubectl run --generator=deployment/apps.v1beta1 is DEPRECATED and will be removed in a future version. Use kubectl create instead.
If you don't see a command prompt, try pressing enter.
进入后执行nslookup kubernetes.default确认解析正常
[ root@curl-5cc7b478b6-r997p:/ ]$ nslookup kubernetes.default
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes.default
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
2.5 2.5 向Kubernetes集群中添加Node节点
下面将node这个主机添加到Kubernetes集群中,在node上执行:
# kubeadm join 192.168.0.7:6443 --token 7zcs8r.pb3q6gy3h8lr0jtk \
--discovery-token-ca-cert-hash sha256:be3d09eb491473867530cb2645b2e36832dd6e6e20e365fcbd3fd2dbea120a9e在master节点上执行命令查看集群中的节点:
# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready master 57m v1.15.0
k8s-node Ready <none> 11s v1.15.0重点查看STATUS内容为Ready时,则说明集群状态正常。
创建Pod以验证集群是否正常。
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pod,svc2.5.1 2.5.1 如何从集群中移除Node
如果需要从集群中移除node这个Node执行下面的命令:
在master节点上执行:
# kubectl drain node --delete-local-data --force --ignore-daemonsets
# kubectl delete node node在node2上执行:
# kubeadm reset
# ifconfig cni0 down
# ip link delete cni0
# ifconfig flannel.1 down
# ip link delete flannel.1
# rm -rf /var/lib/cni/2.6 2.6 部署Dashboard
注:在master节点上进行如下操作
创建Dashboard的yaml文件
wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
sed -i 's/k8s.gcr.io/loveone/g' kubernetes-dashboard.yaml
sed -i '/targetPort:/a\ \ \ \ \ \ nodePort: 30001\n\ \ type: NodePort' kubernetes-dashboard.yaml部署Dashboard
kubectl create -f kubernetes-dashboard.yaml创建完成后,检查相关服务运行状态
kubectl get deployment kubernetes-dashboard -n kube-system
kubectl get pods -n kube-system -o wide
kubectl get services -n kube-system
netstat -ntlp|grep 30001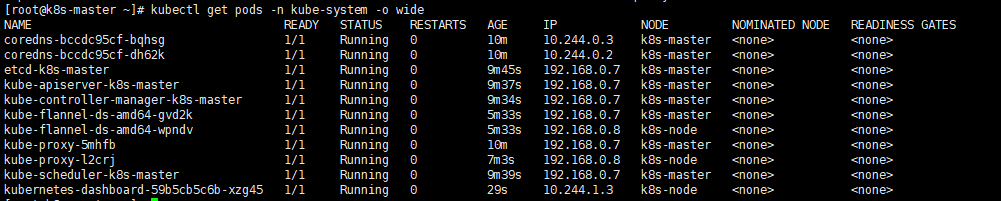
在Firefox浏览器输入Dashboard访问地址:https://192.168.0.7:30001
为什么要使用Firefox浏览器,因为证书有问题,只有Firefox能访问。
2.6.1 2.6.1 解决Google浏览器不能打开kubernetes dashboard方法

这个问题很困扰使用者,那么我们就来看看如何通过谷歌浏览器打开自己部署的kubernetes UI界面。
mkdir key && cd key
#生成证书
openssl genrsa -out dashboard.key 2048
openssl req -new -out dashboard.csr -key dashboard.key -subj '/CN=192.168.0.7'
openssl x509 -req -in dashboard.csr -signkey dashboard.key -out dashboard.crt
#删除原有的证书secret
kubectl delete secret kubernetes-dashboard-certs -n kube-system
#创建新的证书secret
kubectl create secret generic kubernetes-dashboard-certs --from-file=dashboard.key --from-file=dashboard.crt -n kube-system
#查看pod
kubectl get pod -n kube-system
#重启pod
kubectl delete pod <pod name> -n kube-systempod name即dashboard pod name
完成以上操作之后我们重新刷新一下谷歌浏览器 这个时候我们就可以通过谷歌浏览器打开kubernetes dashboard了
查看访问Dashboard的认证令牌
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
使用输出的token登录Dashboard。
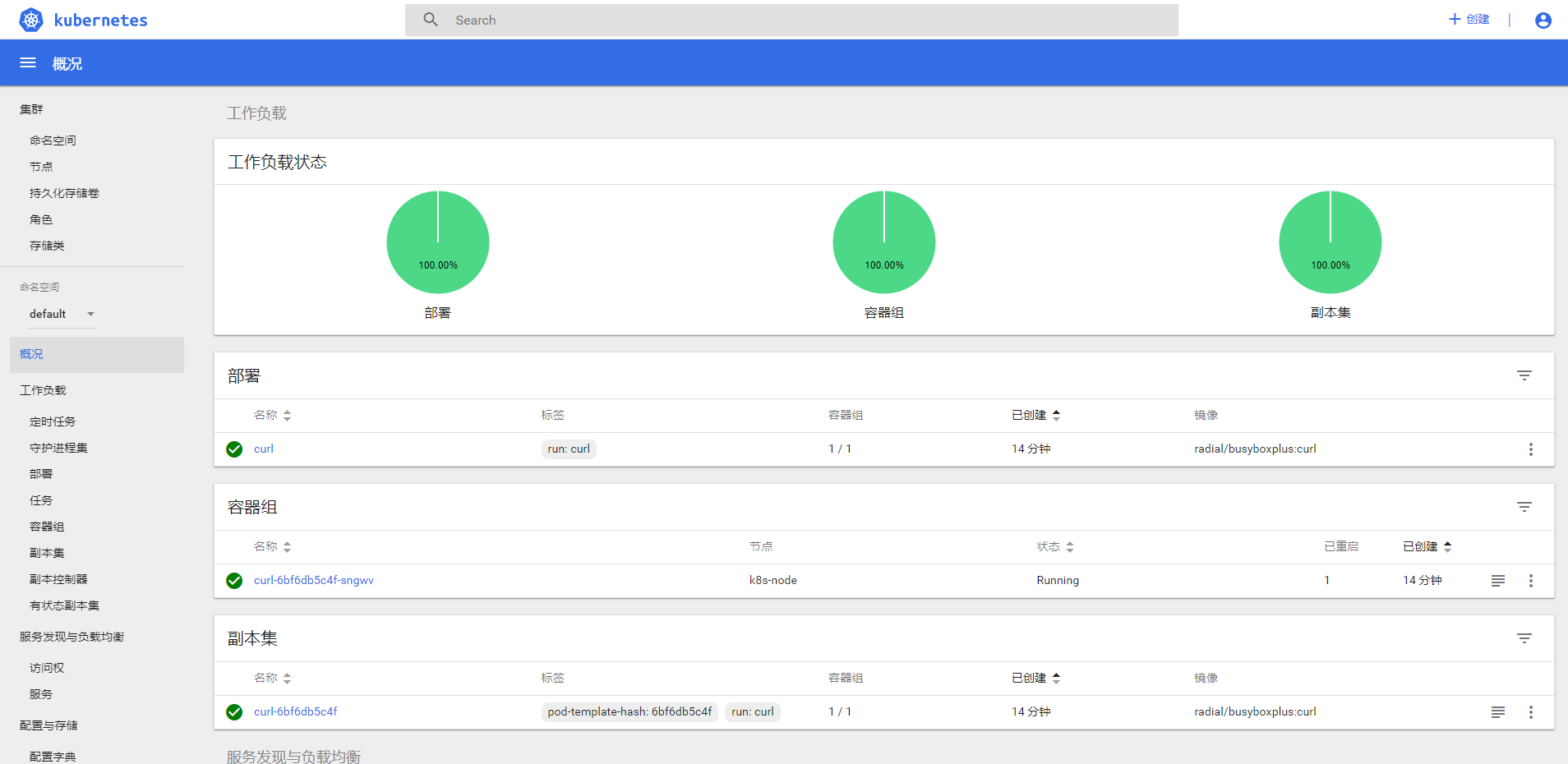
认证通过后,登录Dashboard首页如图
2.7 2.7 kube-proxy开启ipvs
修改ConfigMap的kube-system/kube-proxy中的config.conf,mode: “ipvs”
# kubectl edit cm kube-proxy -n kube-system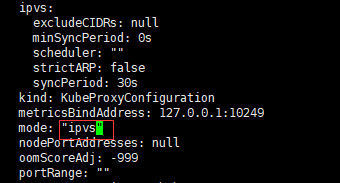
之后重启各个节点上的kube-proxy pod
# kubectl get pod -n kube-system | grep kube-proxy | awk '{system("kubectl delete pod "$1" -n kube-system")}'# kubectl get pod -n kube-system | grep kube-proxy
kube-proxy-8hkh5 1/1 Running 0 67s
kube-proxy-kdgzk 1/1 Running 0 58skubectl logs kube-proxy-8hkh5 -n kube-system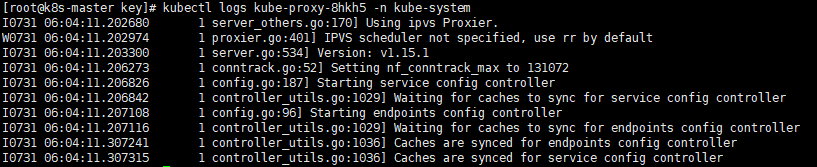
日志中打印出了Using ipvs Proxier,说明ipvs模式已经开启。
2.7.1 2.7.1 Kubernetes Node节点执行 kubectl get all 错误:The connection to the server localhost:8080 was refused.
# kubectl get all
The connection to the server localhost:8080 was refused - did you specify the right host or port?使用 netstat -ntlp 命令检查是否监听了localhost:8080端口,发现并没有。而在Master节点上使用kubectl命令虽然不会报错,但其8080端口仍然未被监听。
事实上,kubectl命令是通过kube-apiserver接口进行集群管理。该命令可以在Master节点上运行是因为kube-apiserver处于工作状态:
# docker ps | grep apiserver
而同时,在Node节点上只有kube-proxy和kubelet处于工作状态:
# docker ps
因此,kubectl命令其实不是为Node节点的主机准备的,而是应该运行在一个Client主机上:如K8s-Master节点的非root用户。当我们kubeadm init success后,系统会提示我们将admin.conf文件保存到Client主机上:
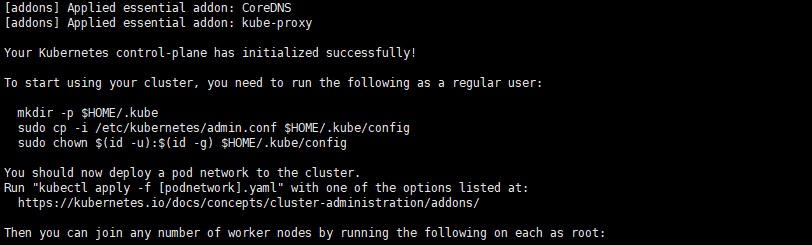
我们查看/etc/kubernetes/admin.conf文件
即可发现,当Client使用该config文件启动kubelet后,他将访问Master节点的6443端口获得数据(Master 6443端口是处于LISTEN状态的),而非localhost:8080端口(因为Node节点无法找到该config文件)。我们也可以把Client客户端放在其他主机中,甚至Node节点。只要将该config文件按照系统提示方式添加到Client客户端中即可。我们使用scp命令将文件发送至目标主机:
将/root/.kube文件夹发至目标主机
scp -r .kube/ 192.168.0.8:/root即可实现使用kubectl访问Master节点。
# kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-master Ready master 56m v1.15.1
k8s-node Ready <none> 52m v1.15.1也就是说,我们正常向Master注册pod的过程也是在Client客户端完成的,而非在Node节点或Master节点完成。